What ZKML AI 2026 Actually Means
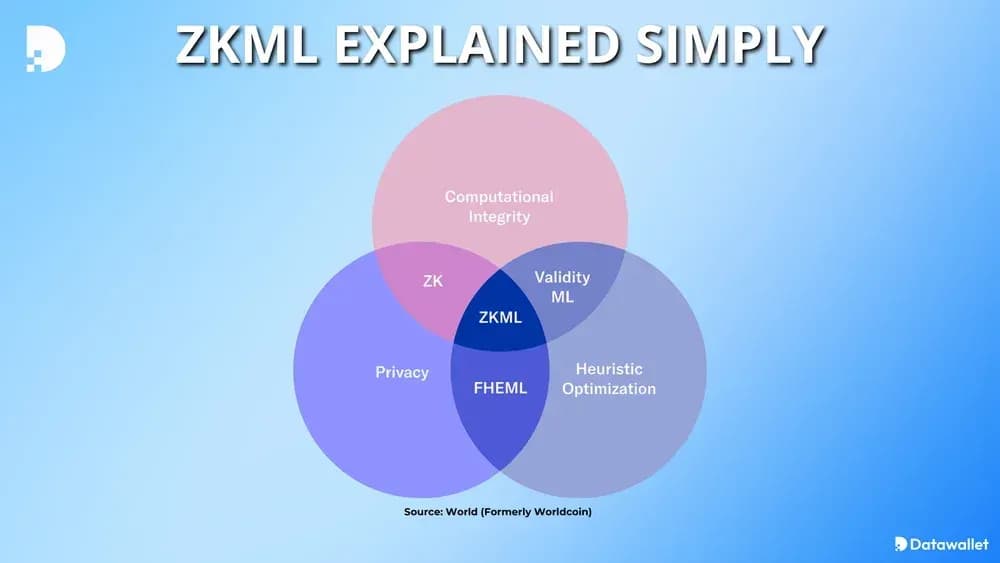
Zero-Knowledge Machine Learning (ZKML) combines zero-knowledge proofs with machine learning to verify AI outputs without exposing the underlying data or model weights. This technology allows anyone to verify that an AI model was executed correctly, ensuring integrity without sacrificing privacy. In an era where data sensitivity is paramount, ZKML provides a way to validate AI decisions without revealing the sensitive information that powered them.
How ZKML Works
At its core, ZKML generates a cryptographic proof that a specific computation was performed correctly on specific inputs. Think of it like a sealed envelope: you can prove the letter inside matches a specific format or contains a correct answer without ever opening the envelope to read the contents. For enterprises, this means you can audit an AI model’s decision-making process without exposing proprietary algorithms or customer data.
Why It Matters for 2026
As AI becomes more embedded in enterprise workflows, the need for verifiable trust grows. ZKML addresses this by providing a mathematical guarantee of correctness. This is particularly important for high-stakes industries like finance and healthcare, where regulatory compliance and data privacy are non-negotiable. By 2026, ZKML is expected to become a standard tool for enterprises seeking to deploy AI with confidence.
Why 2026 Is the Inflection Point
For years, zero-knowledge machine learning (ZKML) lived in the realm of academic papers and theoretical security proofs. The technology was sound, but it was too slow and too complex for real-world deployment. That dynamic is shifting rapidly as the infrastructure matures from experimental codebases into production-ready systems.
The primary driver of this shift is the emergence of the ZK-FHE stack, which combines zero-knowledge proofs with fully homomorphic encryption. By late 2026, this stack is predicted to become the standard for sensitive cloud computations, allowing enterprises to verify AI outputs without exposing the underlying data or model weights [[src-serp-1]].
Simultaneously, developer tooling has improved significantly. Better libraries and standardized interfaces mean that engineering teams can now integrate verifiable privacy into existing workflows without rebuilding their entire stack from scratch [[src-serp-3]]. We are finally seeing ZKML move from academic papers to real infrastructure, with partnerships like the one between Cysic and Inference Labs demonstrating that these tools can handle the computational demands of modern AI [[src-serp-4]].
Verifying Financial Compliance
Financial institutions face a paradox: regulators demand transparency, but privacy laws and competitive pressures forbid sharing raw customer data. ZKML AI resolves this by allowing banks to prove their AI models are compliant without exposing the underlying transactions or customer identities.
The process works like a digital notary stamp. Instead of sending sensitive transaction logs to an auditor, a bank runs its anti-money laundering (AML) model and generates a cryptographic proof. This proof verifies that the decision was made correctly according to regulatory rules, while the actual data remains encrypted and hidden.
- Data Isolation: Customer transaction data stays within the bank’s secure environment. It never leaves the private infrastructure.
- Model Execution: The AI model processes the data locally to flag suspicious activity based on current AML/KYC regulations.
- Proof Generation: The system creates a zero-knowledge proof attesting that the model executed correctly and adhered to the required logic.
- Verification: Regulators or auditors verify the proof on-chain or via a secure portal. They confirm compliance without ever seeing the raw data.
This approach allows institutions to adopt AI for compliance checks while maintaining strict data sovereignty. It shifts the burden of proof from "show us your data" to "prove your logic is sound," a critical evolution for 2026-era enterprise AI.
Protecting Health Data in Diagnostics
Healthcare providers face a dual mandate: deliver accurate diagnoses and protect patient privacy. ZKML allows hospitals to verify that an AI model produced a correct result without exposing the underlying patient records or the proprietary model weights.
How ZKML secures diagnostic AI
The process relies on zero-knowledge proofs generated during inference. When a diagnostic AI analyzes medical images or records, it creates a cryptographic proof that the computation was performed correctly on valid data. This proof is verified by the hospital system before the result is accepted.
- Input Encryption: Patient data is encrypted before entering the AI pipeline.
- Proof Generation: The AI model runs on the encrypted data and generates a ZK-SNARK proof of correct inference.
- Verification: The hospital’s system verifies the proof. If valid, the diagnostic result is released.
- Audit Trail: The proof serves as an immutable record that the AI followed the approved protocol, without revealing patient details.
This approach ensures compliance with regulations like HIPAA while maintaining trust in AI-driven diagnostics. Providers can deploy third-party AI models without risking data leaks, as the system only validates the output, not the input data itself.
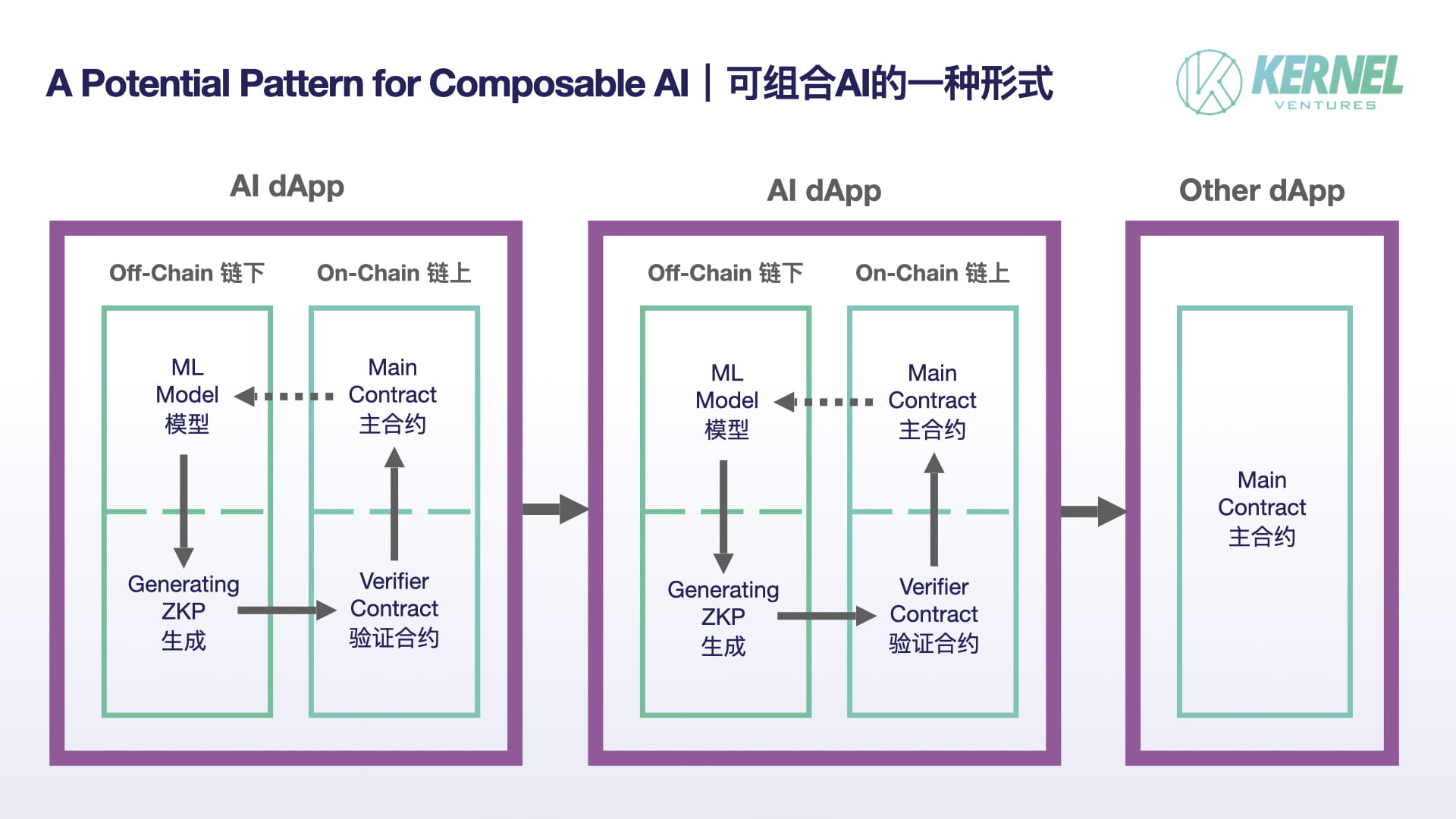
Securing autonomous agent memory
As AI agents move from isolated tools to coordinated teams, they face a new coordination problem: how to share context without exposing sensitive data. In 2026, ZKML enables trustless shared memory, allowing multiple agents to coordinate on complex tasks while keeping proprietary or private information encrypted and verifiable.
This architecture shifts memory from a centralized, vulnerable database to a decentralized, verified ledger. Agents can prove they have access to necessary credentials or historical context without revealing the actual data to other agents or external observers. This is critical for enterprise workflows where agents from different vendors or departments must collaborate on sensitive projects.
The implementation relies on zero-knowledge proofs to validate memory access. When Agent A queries a shared memory space, it receives a proof that the data exists and matches its permissions, without seeing the underlying plaintext. This prevents data leakage during high-stakes operations like financial auditing or healthcare record processing.
Overcoming Compute Latency
Generating zero-knowledge proofs for large machine learning models has historically required significant computational overhead. In 2026, this latency is no longer a blocker for enterprise adoption. New optimizing systems like ZKML have reduced proof generation time significantly by streamlining the circuit construction process.
The workflow for mitigating this latency follows a specific sequence:
Choose a framework that supports direct ML model compilation. Tools like the ZKML optimizing system (ACM 2024) allow developers to bypass manual circuit design, automatically generating efficient ZK-SNARKs for vision and language models.

Run the model through the compiler to generate the verification circuit. The system optimizes arithmetic constraints for the specific hardware, reducing the computational cost of the proof generation phase without sacrificing accuracy.

Deploy the compiled model to your enterprise environment. The system handles the heavy lifting of proof generation in the background, ensuring that verification remains fast enough for real-time or near-real-time enterprise workflows.
This shift from manual optimization to automated compilation is what allows ZKML to scale. Enterprises can now deploy verifiable AI without waiting hours for a single proof to generate.
Implementing ZKML in Your Stack
Integrating zero-knowledge machine learning (ZKML) requires shifting from standard inference pipelines to proof-generation workflows. Engineering teams must treat proof generation as a first-class citizen in their architecture, not an afterthought.
1. Verify Proof System Compatibility
Before selecting a provider, audit your existing model architecture against supported proof systems. Most current ZKML frameworks favor specific circuit representations, such as those based on PLONK or STARKs. Ensure your target model (e.g., Transformer or CNN) can be effectively compiled into the required arithmetic circuits without prohibitive overhead.
2. Assess Latency and Throughput Impact
Proof generation is computationally expensive. Benchmark your current inference latency against the additional time required to generate and verify proofs. In high-throughput environments, you may need to implement asynchronous proof generation queues to prevent blocking real-time user requests. The goal is to balance verifiability with acceptable response times for your specific use case.
3. Evaluate Developer Tooling and Ecosystem
Mature dev tooling significantly reduces integration friction. Look for providers that offer SDKs compatible with your primary language (Python, Rust, or Go) and clear documentation for circuit compilation. As noted in industry guides, better tooling is a primary driver for ZKML adoption in 2026, making the developer experience a critical selection criterion.
4. Define Verification Strategy
Decide where verification occurs. On-chain verification offers maximum trust but incurs gas costs and strict computational limits. Off-chain verification with Merkle root anchoring is often more practical for enterprise backends. Ensure your chosen strategy aligns with your compliance requirements and infrastructure capabilities.
-
Verify proof system compatibility with your model architecture
-
Assess latency impact on real-time inference pipelines
-
Check support for specific model types (CNNs, Transformers)
No comments yet. Be the first to share your thoughts!