
In an era where AI models process vast amounts of sensitive data, particularly in financial analysis, the black-box nature of traditional inference poses significant risks. Verifiable AI pipelines powered by zero-knowledge machine learning (zkML) and ONNX hashing address this by enabling cryptographic guarantees that outputs stem from correct model execution on private inputs. This approach aligns with conservative investment principles, prioritizing data integrity and long-term stability over unchecked innovation.

ONNX, an open-standard format for machine learning models, facilitates seamless interoperability across frameworks like PyTorch and TensorFlow. When integrated with zkML, it allows model providers to commit to a fixed version via hashing, proving inference fidelity without revealing proprietary weights or user data. Recent developments underscore this potential; for instance, frameworks now support quantization to fixed-point arithmetic, essential for efficient ZK-SNARK generation in zkML ONNX inference.
Core Principles of Verifiable AI Pipelines
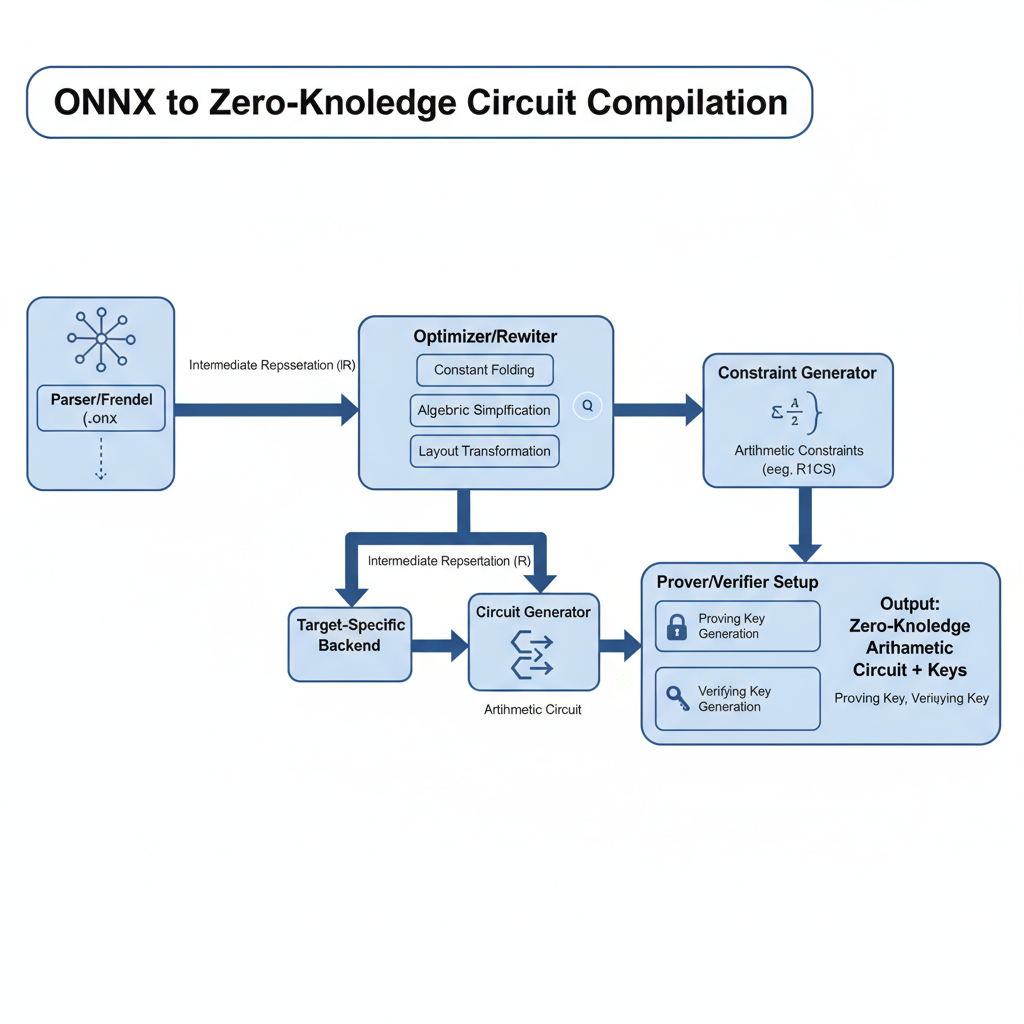
At its heart, a verifiable AI pipeline relies on zero-knowledge proofs, where the prover demonstrates computation correctness to a verifier without disclosing inputs. In zkML, this extends to neural networks: export a model to ONNX, quantize layers, compile into arithmetic circuits, and generate proofs. Verification times often undercut full inference, preserving value even for public inputs. This efficiency stems from optimized systems like those producing ZK-SNARKs for vision models or distilled language models.

Conservatively, zkML mitigates risks in autonomous AI agents, such as those in decentralized finance. By hashing the ONNX model, participants confirm the exact version used, preventing tampering. Quantization, while introducing minor precision trade-offs, ensures practicality; benchmarks show proofs for complex models in seconds on standard hardware.
Key Benefits of zkML ONNX Hashing
- Privacy Preservation: Enables verifiable AI inference with private inputs without exposing data, as in Mina Protocol's zkML library and Zkonduit's ezkl.

- Model Commitment via Hash: ONNX model hashing commits to a fixed model, proving outputs from specified version using ZK-SNARKs.

- Fast Verification: ZK proofs verify faster than full inference execution, per ZKML analyses.
- Interoperability: ONNX supports models from PyTorch/TensorFlow, as in ICME and Polyhedra zkPyTorch frameworks.
- Edge Device Support: Lightweight ONNX enables ML inference on mobile/edge devices via zkML libraries.

Landmark Frameworks Advancing zkML ONNX Inference
Mina Protocol's zkML library stands out, empowering developers to generate proofs from AI inference jobs with private inputs directly from ONNX models. Similarly, Zkonduit's ezkl simplifies ZK proof creation for ONNX-exported neural networks, democratizing access without deep cryptographic knowledge.
Production advancements include ICME's framework, which processes PyTorch or TensorFlow models via ONNX into JOLT-Atlas proofs, ideal for scalable autonomous commerce. Polyhedra's zkPyTorch compiles models into verifiable circuits, achieving 2.2 seconds per image for VGG-16 on single-core CPUs. Inference Labs' JSTprove offers a command-line toolkit for ONNX-to-circuit conversion, abstracting complexities for reproducible inference in verifiable AI pipelines.
Establishing a zkML Proof Pipeline: Prerequisites
Building your first zkML ONNX hashing pipeline begins with model preparation. Select a framework-supporting model, such as a quantized ResNet for image classification, and export to ONNX using standard tools. Hash the file to establish commitment; this SHA-256 digest serves as the immutable reference in proofs.
Next, choose a zkML engine. For conservative setups, prioritize those with audited circuits and proven benchmarks, like ezkl or Mina's library. Install dependencies via pip, ensuring fixed-point compatibility to sidestep floating-point challenges inherent in neural network inference. Environment setup typically involves Rust for provers and a compatible backend like Halo2.
With prerequisites in place, proceed to model export. Use PyTorch's torch. onnx. export function, specifying opset_version=11 for broad compatibility and enabling quantization via post-training scripts. This converts floating-point operations to integers, crucial for zkML ONNX inference where circuits demand fixed precision.
Build Secure zkML Pipelines: ONNX Export to ZK Verification
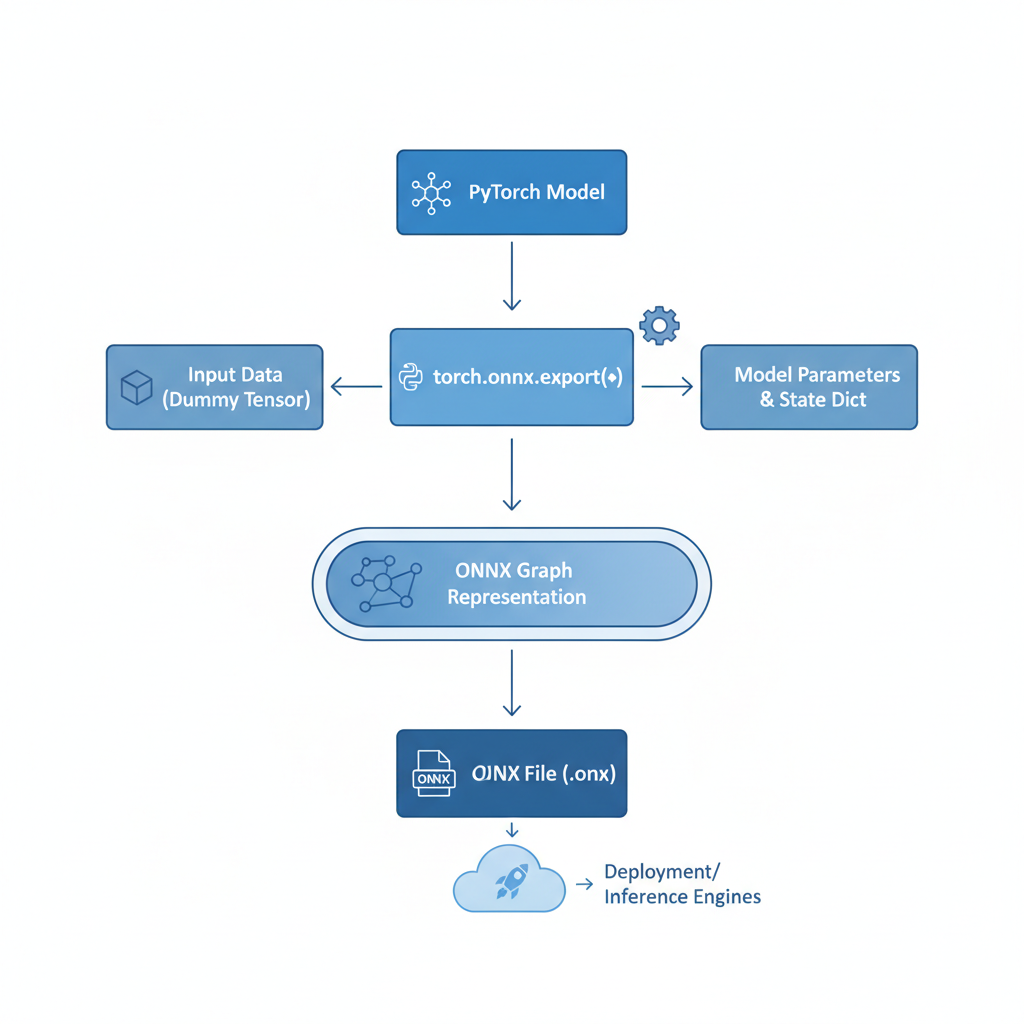
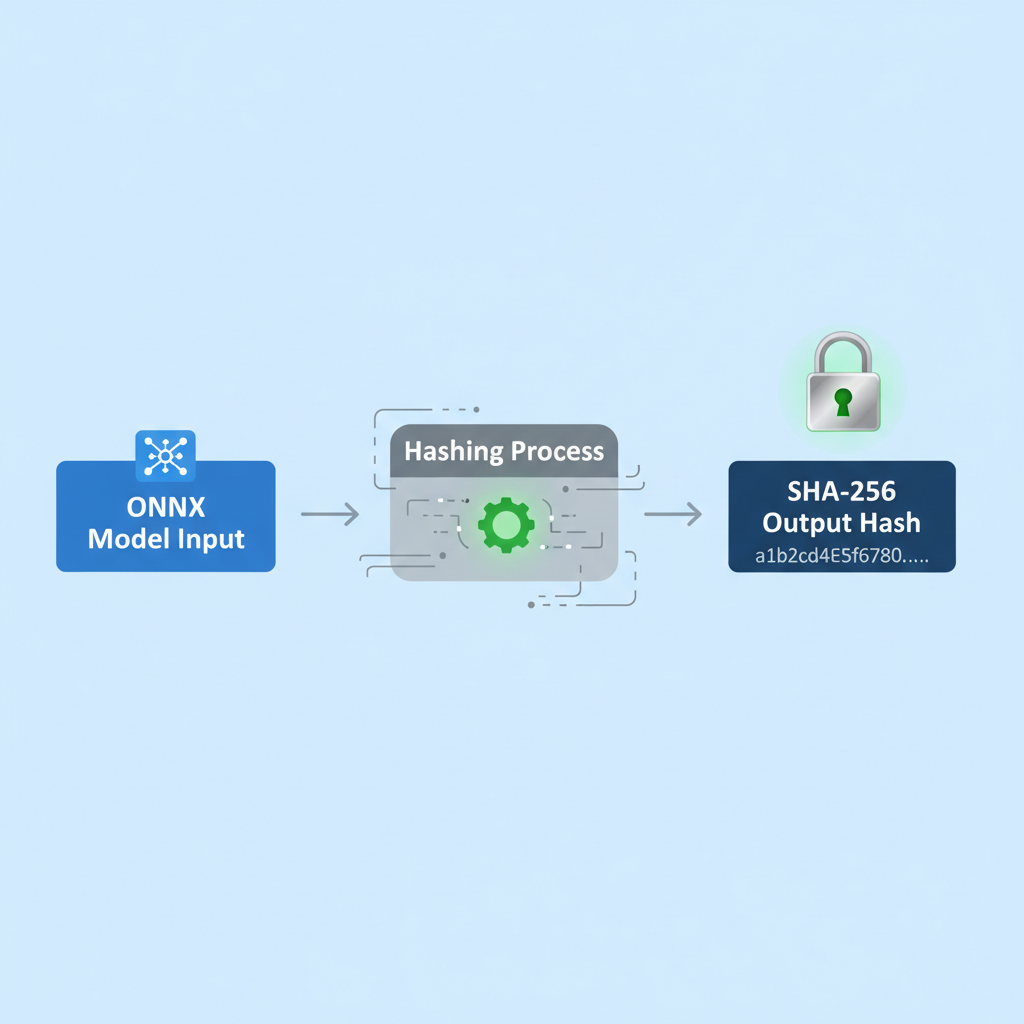
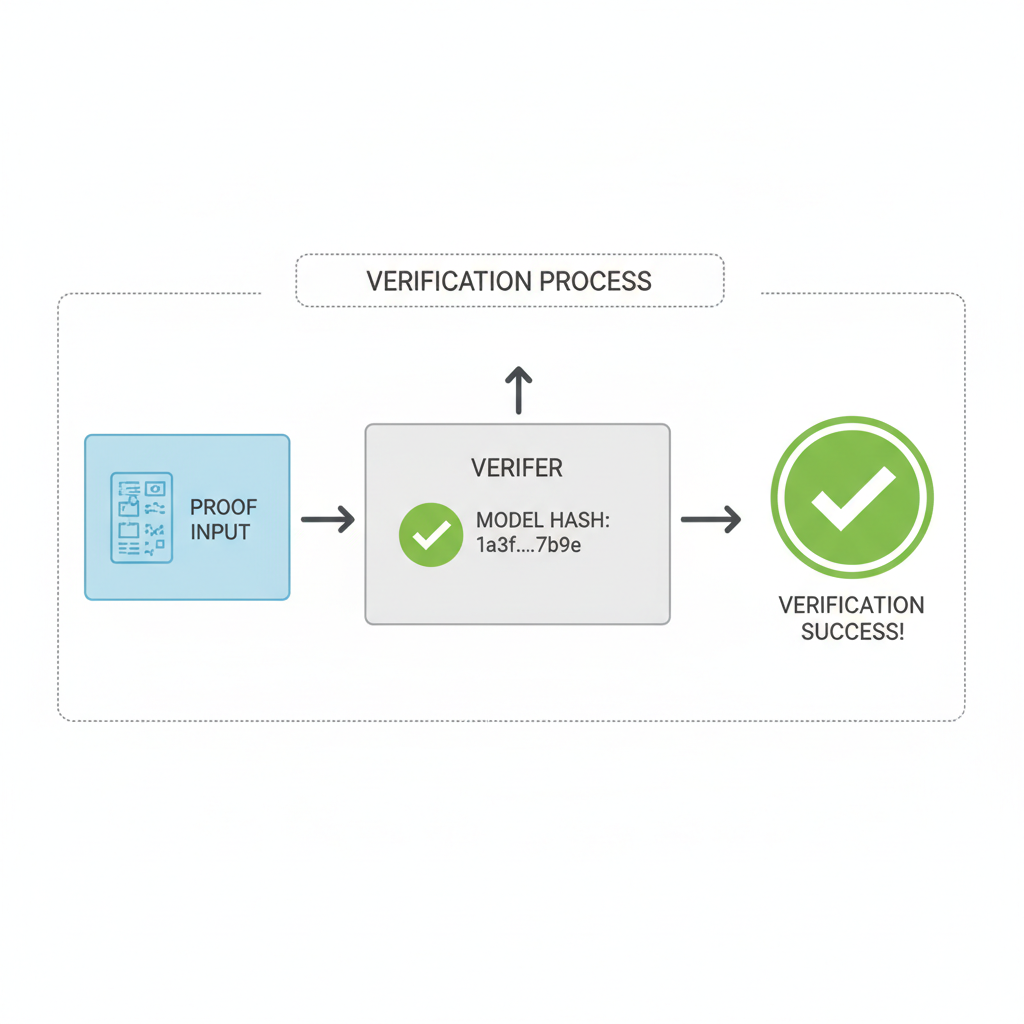
Hashing the ONNX file anchors the pipeline's integrity. Compute the SHA-256 digest; this hash embeds in the proof, allowing verifiers to confirm the exact model version without access to weights. In verifiable AI pipelines, this commitment prevents subtle attacks like model poisoning, a conservative safeguard for financial models analyzing balance sheets or market trends.
Model Hashing and ZK Proof Generation
To establish a verifiable pipeline, first compute the SHA-256 hash of the ONNX model file using Python's hashlib library. This hash serves as a fingerprint for model integrity verification. Next, employ the ezkl command-line tool, invoked via subprocess, to generate the zero-knowledge proof for the AI inference.
import hashlib
import subprocess
# Compute SHA-256 hash of the ONNX model
def compute_model_hash(model_path):
hash_sha256 = hashlib.sha256()
with open(model_path, "rb") as f:
while chunk := f.read(4096):
hash_sha256.update(chunk)
return hash_sha256.hexdigest()
model_path = "model.onnx"
model_hash = compute_model_hash(model_path)
print(f"Model SHA-256 hash: {model_hash}")
# Generate ZK proof using ezkl
ezkl_cmd = [
"ezkl",
"gen-proof",
"--model", model_path,
"--vk", "vk.key",
"--proof", "proof.json",
"--input", "input.json",
"--strategy", "eve"
]
result = subprocess.run(ezkl_cmd, capture_output=True, text=True)
if result.returncode == 0:
print("ZK proof generated successfully.")
else:
print("Error generating proof:", result.stderr)The computed hash enables straightforward integrity checks against known values. The resulting ZK proof mathematically attests to the fidelity of the inference computation without exposing sensitive data, forming a foundational element of the verifiable pipeline.
Compilation follows, transforming the ONNX graph into an arithmetic circuit. Tools like ezkl or JSTprove automate this, handling layer-wise quantization and optimization. For instance, Inference Labs' JSTprove streamlines ONNX-to-circuit conversion through a command-line interface, making verifiable AI pipelines accessible even to teams without cryptography specialists. Benchmarks from Polyhedra's zkPyTorch reveal proof times as low as 2.2 seconds for VGG-16 inference, balancing speed with reliability on consumer hardware.
Generating and Verifying zkML Proofs
Proof generation invokes the prover on private inputs against the committed model. In a zkML ONNX inference workflow, supply the hashed model, quantized inputs, and witness data to produce a succinct ZK-SNARK. Verification is swift; a 128-bit proof checks in milliseconds, far outpacing re-execution of a ResNet-50 forward pass.
This verifiability extends to aggregation, where multiple proofs compress into one via techniques like recursive SNARKs. zkML proof aggregation enhances scalability for batch inference in high-stakes scenarios, such as portfolio optimization where dozens of models process confidential trade data. Conservatively, aggregation reduces on-chain costs in decentralized setups, aligning with value investing's emphasis on efficiency without excess risk.
ICME's production framework exemplifies this, leveraging JOLT-Atlas for proofs from ONNX-exported models, enabling AI agents in autonomous commerce with mathematical certainty. Mina's zkML library complements by supporting private-input proofs directly, ideal for edge devices running lightweight ONNX models.
Practical Applications in Financial Analysis
For fundamental analysts, zkML ONNX hashing secures proprietary models evaluating earnings quality or credit risk. Imagine proving a neural net's output on private filings without exposing strategies; the hash confirms model fidelity, proofs attest computation, fostering trust in DeFi lending protocols or tokenized funds. This mitigates oracle risks, where tampered inferences could erode capital.
Challenges persist: quantization approximates results, demanding rigorous accuracy testing. Larger models strain prover times, though optimizations like those in ZKML frameworks narrow the gap. A conservative stance favors smaller, audited models over bleeding-edge giants, prioritizing stability in verifiable AI pipelines.
Edge deployment shines too; ONNX's portability suits mobile or IoT for real-time zkML ONNX inference, with proofs offloaded to cloud verifiers. As frameworks mature, from Kudelski's ezkl to 0xPARC's initiatives, the ecosystem solidifies for privacy-preserving AI.
Deploying these pipelines demands iterative testing: benchmark proof sizes, verify against golden outputs, and simulate adversarial inputs. Success yields resilient systems, where AI augments decisions with cryptographic backing, echoing timeless principles of verifiable computation in an AI-driven market.




No comments yet. Be the first to share your thoughts!